
Introduction
La gestion des erreurs est une partie essentielle de RxJs, massivement utilisée dans le framework Angular.
La gestion des erreurs dans RxJS n’est pas aussi bien comprise que d’autres parties de la bibliothèque du même nom, en partie à cause d’une méconnaissance générale du « contrat Observable ».
Dans cet article, nous allons donc fournir un guide complet contenant les stratégies de gestion des erreurs les plus courantes utilisés dans les milieux professionnels, en commençant par expliquer les bases : le « contrat Observable ».
Le contrat Observable et la gestion des erreurs
Afin de bien comprendre la gestion des erreurs dans RxJs, il est indispensable de bien comprendre quelques notions indispensables. Premièrement, un flux de données (stream) ne peut s’arrêter qu’une seule fois. Un flux peut également se terminer normalement, ce qui signifie que :
- le flux a terminé son cycle de vie sans aucunes erreurs.
- une fois terminé, le flux n’émettra plus rien.
Comme alternative à l’achèvement, un flux peut également générer une erreur, ce qui signifie que :
- le flux a terminé son cycle de vie avec une erreur.
- une fois l’erreur levée, le flux n’émettra aucune autre valeur.
Notons que l’achèvement ou l’erreur s’excluent mutuellement :
- si le flux se termine, il ne peut pas générer d’erreur par la suite.
- si les flux produisent des erreurs, ils ne peuvent pas se terminer par la suite.
Notez également qu’il n’y a aucune obligation pour le flux de se terminer ou de sortir une erreur, ces deux possibilités sont facultatives. Mais un seul de ces deux peut se produire, pas les deux.
Cela signifie que lorsqu’un flux particulier se trompe, nous ne pouvons plus l’utiliser, selon le « contrat Observable ». Il faut toujours avoir à l’esprit ce principe, car c’est souvent ici qu’on retrouve des faiblesses dans le code.
A ce stade, il est donc très important de se poser la question : comment gérer des erreurs non prévues ?
Souscription RxJs et rappels d’erreurs
Pour connaître le comportement des erreurs RxJs, rien de mieux qu’un exemple. Créons un flux et souscrivons-y tout de suite. Rappelons à toutes fins utiles que subscribe() prend trois arguments optionnels :
- une fonction rappel de succès, qui est appelée chaque fois que le flux émet une valeur.
- une fonction rappel d’erreurs, qui est appelée uniquement si une erreur se produit. La fonction reçoit en paramètre l’erreur elle-même.
- une fonction rappel d’achèvement, qui est appelée uniquement si le flux se termine.
@Component({
selector: 'app',
templateUrl: './app.component.html'
})
export class AppComponent implements OnInit {
constructor(private http: HttpClient) {}
ngOnInit() {
const http$ = this.http.get<Post[]>('/api/posts');
http$.subscribe({
next: res => console.log('HTTP response ok.', res),
error: err => console.log('HTTP Error.', err),
complete: () => console.log('HTTP request completed.')
}
);
}
}Exemple de comportement d’achèvement
Si le flux ne génère pas d’erreur, voici ce qu’affiche la console :
[Log] HTTP response ok. (vendor.js, line 5673)
[Log] HTTP request completed. (vendor.js, line 5699)Comme nous pouvons le voir, ce flux HTTP n’émet qu’une seule valeur, puis il se termine, ce qui signifie qu’aucune erreur ne s’est produite.
Mais que se passe-t-il si le flux génère une erreur à la place ? Dans ce cas, nous verrons plutôt ce qui suit dans la console :
[Error] XMLHttpRequest cannot load http://localhost:8080/api/ due to access control checks.
[Log] HTTP Error. – HttpErrorResponse {headers: HttpHeaders, status: 0, statusText: "Unknown Error", …} (vendor.js, line 5685)Comme nous pouvons le voir, le flux n’a émis aucune valeur et il a immédiatement généré une erreur. Après l’erreur, rien ne s’est produit.
Limitations du gestionnaire d’erreurs d’abonnement
La gestion des erreurs à l’aide de la fonction de rappel de subscribe() peut parfois suffire, mais cette approche est limitée. En l’utilisant, nous ne pouvons pas, par exemple, continuer le script ou émettre une valeur de secours alternative qui remplacerait la valeur attendue.
Voyons maintenant comment récupérer de ces erreurs aléatoires, à l’aide des opérateurs RxJs.
L’opérateur catchError
En programmation synchrone, nous avons la possibilité d’envelopper un bloc de code dans une clause « try » et d’intercepter toute erreur qui pourrait générée à l’aide d’un bloc catch, puis de gérer la dite erreur.
Voici à quoi ressemble la syntaxe de capture synchrone :
try {
// synchronous call
const httpResponse = HttpClient('/api/posts');
}
catch(error) {
// handle error
}Ce mécanisme est très puissant car nous pouvons gérer en un seul endroit toute erreur qui se produit à l’intérieur du bloc try/catch.
Le problème est qu’en Javascript, de nombreuses opérations sont asynchrones, et un appel HTTP est un parfait exemple où les choses se produisent de manière asynchrone.
C’est là qu’entre en scène l’opérateur catchError.
Comment fonctionne catchError ?
Comme d’habitude et comme avec tout opérateur RxJs, catchError est simplement une fonction qui prend en entrée un « Observable » et renvoie aussi un « Observable ».
A chaque appel à catchError, nous devons lui passer une fonction que nous appellerons la fonction de gestion des erreurs.
L’opérateur catchError prend en entrée un « Observable » susceptible de provoquer une erreur. Avant que cela n’arrive, les valeurs passées en entrées sont directement reproduites en sortie.
Si aucune erreur ne se produit, l ‘ « Observable » produit par catchError sera le même que celui passé en entrée.
Que se passe-t-il lorsqu’une erreur est générée ?
Cependant, si une erreur se produit, la logique catchError va se déclencher. L’opérateur va prendre l’erreur et la transmettre à la fonction de gestion des erreurs.
Cette fonction est censée émettre un « Observable de remplacement » pour le flux qui vient de générer une erreur.
Rappelons-nous que le flux d’entrée de catchError a généré une erreur, donc selon le « contrat Observable » , nous ne pouvons plus l’utiliser.
C’est pour cette raison qu’un nouvel « Observable » a été émis, et c’est lui qui devra être utilisé dans le flux.
La stratégie « Catch and Replace » (capture et de remplacement)
Ci-arpès un exemple d’utilisation de catchError :
const http$ = this.http.get<Post[]>('/api/posts');
http$
.pipe(
catchError(err => of([])) ①
)
.subscribe({
next: res => console.log('HTTP response', res),
error: err => console.log('HTTP Error', err),
complete: () => console.log('HTTP request completed.')
}
);Qu’avons nous fait ? Une petite explication s’impose :
- d’abord nous passons à l’opérateur catchError une fonction, qui est la fonction de gestion des erreurs de tout à l’heure (①)
- cette fonction n’est pas appelée immédiatement, et en général, elle ne l’est que très rarement
- uniquement lorsque le flux http$ provoque une erreur
- le cas échéant, un « Observable » sera émis par la fonction of(), ayant pour unique valeur un tableau vide ([])
- la fonction of() construit un « Observable » qui n’émet qu’une seule valeur ([]) puis se termine
- l’opérateur catchError va ensuite souscrire à ce nouvel « Observable », la valeur émise va donc remplacer la ou les valeurs du flux initial (http$)
-> Au final, le flux http$ n’émettra plus d’erreur !
Voici le résultat que nous obtenons dans la console :
[Log] HTTP response ok.
[Log] HTTP request completed. (vendor.js, line 5699)Comme nous pouvons le voir, la fonction rappel de gestion des erreurs définie dans subscribe() n’est plus invoquée. Au lieu de cela, voici ce qui se passe :
- la valeur de tableau vide [] est émise
- le flux http$ est alors complété
Comme nous pouvons le voir, l’ « Observable » de remplacement a bien été utilisé pour fournir une valeur de secours par défaut ([]) aux abonnés du flux http$, malgré le fait que l’ « Observable » d’origine ait généré une erreur.
Notez que nous aurions également pu ajouter une gestion des erreurs locales, avant de renvoyer le remplacement Observable !
Voyons maintenant comment nous pouvons également utiliser catchError pour renvoyer l’erreur, au lieu de fournir des valeurs de secours.
throwError et la stratégie « Catch and Rethrow »
Commençons par remarquer que l’ « Observable » de remplacement fourni par catchError peut lui-même générer une erreur, comme tout autre « Observable ».
Et si cela se produit, l’erreur sera propagée aux abonnés de la sortie « Observable » de catchError.
Ce comportement de propagation des erreurs nous donne un mécanisme pour renvoyer l’erreur interceptée par catchError, après avoir traité l’erreur localement. Nous pouvons le faire de la manière suivante :
const http$ = this.http.get<Post[]>('/api/posts');
http$
.pipe(
catchError(err => { ①
console.log('Handling error locally and rethrowing it...', err); ②
return throwError(() => new Error(err)); ③
})
)
.subscribe({
next: res => console.log('HTTP response ok.', res),
error: err => console.log('HTTP Error.', err),
complete: () => console.log('HTTP request completed.')
}
);Voyons étape par étape le fonctionnement de cette stratégie :
- comme précédemment, nous attrapons l’erreur et renvoyons un « Observable » de remplacement (①)
- mais cette fois-ci, au lieu d’émettre une nouvelle valeur de remplacement, nous gérons l’erreur localement dans la fonction catchError
- on affiche simplement l’erreur dans la console, mais on pourrions à la place ajouter n’importe quelle logique de gestion des erreurs, comme par exemple afficher un message d’erreur à l’utilisateur (②)
- nous renvoyons ensuite un « Observable » de remplacement qui est déjà en erreur, si je puis m’exprimer ainsi, à l’aide de la fonction throwError (③)
- on peut créer une nouvelle erreur ou bien, comme ici, reprendre la même erreur (fournie par le paramètre de catchError)
- cela signifie que nous avons réussi à « relancer » le flux en renvoyant avec succès l’erreur initialement renvoyée par l’entrée « Observable » de catchError vers sa sortie « Observable »
- l’erreur peut maintenant être gérée par le reste de la chaîne « Observable », si nécessaire (plus précisément par la fonction rappel de subscribe())
L’intérêt majeur de cette stratégie est qu’elle nous donne la possibilité de gérer des « side effects » lors des erreurs (logging, alertes etc).
Le code précédent affiche dans la console :
[Log] Handling error locally and rethrowing it… – HttpErrorResponse [Log] HTTP Error. – Error: [object Object] — app.component.ts:24 (vendor.js, line 5685)Error: [object Object] — app.component.ts:24Comme nous pouvons le voir, la même erreur a été enregistrée à la fois dans le bloc catchError et dans la fonction de gestion des erreurs de la fonction subscribe(), comme prévu.
Utilisation de catchError plusieurs fois dans un flux
Notez que nous pouvons, si nécessaire, utiliser catchError plusieurs fois à différents points de la chaîne « Observable », et adopter différentes stratégies d’erreur à différents endroits de la chaîne.
Nous pouvons, par exemple, attraper une erreur dans la chaîne « Observable », la gérer localement et la relancer, puis plus bas dans la chaîne « Observable », nous pouvons à nouveau attraper la même erreur et cette fois fournir une valeur de repli (au lieu de relancer le flux) :
const http$ = this.http.get<Post[]>('/api/posts');
http$
.pipe(
map(res => res['payload']),
catchError(err => {
console.log('caught mapping error and rethrowing', err);
return throwError(err);
}),
catchError(err => {
console.log('caught rethrown error, providing fallback value');
return of([]);
})
)
.subscribe({
next: res => console.log('HTTP response ok.', res),
error: err => console.log('HTTP Error.', err),
complete: () => console.log('HTTP request completed.')
}
);Voilà ce qu’on obtiendrait dans la console :
[Log] caught mapping error and rethrowing – HttpErrorResponse
[Log] caught rethrown error, providing fallback value (main.js, line 78)
[Log] HTTP response ok. – [] (0) (vendor.js, line 5673)
[Log] HTTP request completed. (vendor.js, line 5699)Comme nous pouvons le voir, l’erreur a effectivement été renvoyée initialement, mais elle n’a jamais atteint la fonction de gestion des erreurs de la fonction subscribe(). Au lieu de ça, la valeur de secours [] a été émise, comme prévu.
L’opérateur « finalize »
En plus d’un bloc catch pour gérer les erreurs, la syntaxe Javascript synchrone fournit également un bloc finally pour exécuter du code quoi qu’il se passe dans le bloc try.
Le bloc finally est généralement utilisé pour libérer des ressources coûteuses, comme par exemple fermer des connexions réseau ou libérer de la mémoire.
Contrairement au code du bloc catch, le code du bloc finally sera donc exécuté même si une erreur est générée :
try {
// synchronous operation
const httpResponse = HttpClient('/api/posts');
}
catch(error) {
// handle error, only executed in case of error
}
finally {
// this will always get executed
}RxJs nous fournit un opérateur qui a un comportement similaire au bloc finally, appelé l’opérateur finalize.
Exemple
A l’instar de l’opérateur catchError, il est possible d’ajouter plusieurs appels finalize dans la chaîne « Observable » (ou flux) :
http$
.pipe(
map(res => res['payload']),
catchError(err => {
console.log('caught mapping error and rethrowing', err);
return throwError(err);
}),
finalize(() => console.log("first finalize() block executed")),
catchError(err => {
console.log('caught rethrown error, providing fallback value');
return of([]);
}),
finalize(() => console.log("second finalize() block executed"))
)
.subscribe({
next: res => console.log('HTTP response ok.', res),
error: err => console.log('HTTP Error.', err),
complete: () => console.log('HTTP request completed.')
}
);Ce qui affiche dans notre console :
[Log] caught mapping error and rethrowing – HttpErrorResponse
[Log] caught rethrown error, providing fallback value (main.js, line 79)
[Log] first finalize() block executed (vendor.js, line 5893)
[Log] HTTP response ok. – [] (0) (vendor.js, line 5673)
[Log] HTTP request completed. (vendor.js, line 5699)
[Log] second finalize() block executed (vendor.js, line 5893)Il est intéressant de noter que le dernier bloc finalize est exécuté après les fonctions de rappels de subscribe().
La stratégie « nouvelle tentative » (retry)
Plutôt qu’émettre une nouvelle valeur lors d’une erreur, nous pouvons également simplement réessayer de re-souscrire au flux erroné.
Rappelons-nous, une fois que le flux est sorti en erreur, nous ne pouvons pas le récupérer, mais rien ne nous empêche de nous abonner à nouveau à l’« Observable » dont le flux a été dérivé et de créer un autre flux.
Voici l’idée générale :
- nous allons souscrire une première fois à l’« Observable » http$ ce qui va créer un premier flux
- si ce flux ne génère pas d’erreur, nous allons le laisser se terminer normalement
- par contre, si le flux produit une erreur, nous allons alors souscrire à nouveau à l’« Observable » http$ ce qui va créer un nouveau flux
A quel moment re-souscrire ?
La grande question ici est de savoir quand allons-nous souscrire à nouveau à l’« Observable » http$ et ainsi réessayer d’exécuter le flux d’entrée ? Plusieurs possibilités :
- immédiatement ?
- après un petit délai en espérant que le problème soit résolu ?
- allons-nous réessayer seulement un nombre limité de fois, puis générer une erreur ?
Afin de répondre à cette question, nous allons devoir introduire un nouvel opérateur : retry.
Diagramme marble de l’opérateur retry
Pour comprendre le fonctionnement de l’opérateur retry, examinons son diagramme :
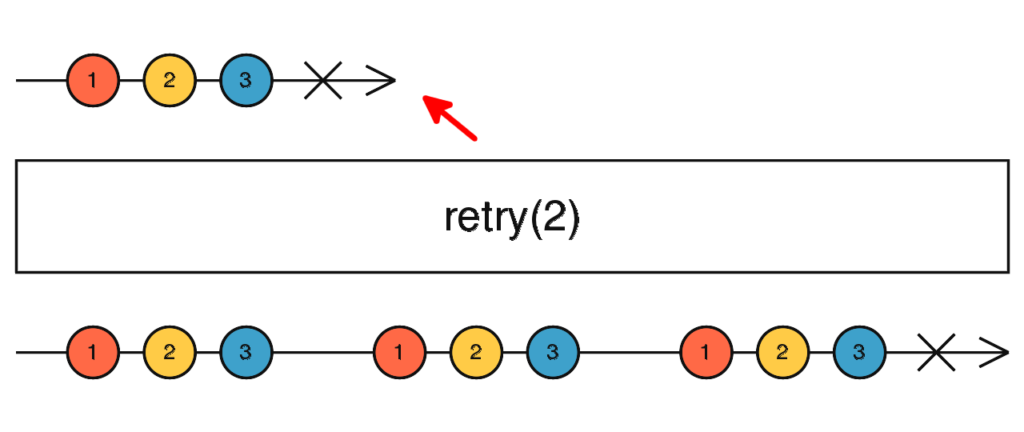
Examinons ce qu’il se passe :
- on souscrit à l’« Observable » http$, ses valeurs sont immédiatement émises (1, 2 puis 3) et directement renvoyée par retry
- le flux se termine mais comme retry a pour paramètre 2, il re-souscrit tout de suite à l’« Observable » http$
- les valeurs 1, 2 et 3 sont de nouveau ré-émises et
- retry souscrit donc à nouveau à l’« Observable » http$, et ses valeurs sont à nouveau émisent vers la sortie « Observable » de retry
- le même schéma se répète une seconde fois, plus le flux se termine mais cette fois retry ne re-souscrit pas une troisième fois !
Maintenant que nous comprenons comment fonctionne retry, voyons comment nous pouvons mettre en oeuvre notre stratégie.
Stratégie « nouvelle tentative immédiate »
Afin de refaire une tentative tout de suite après une erreur, tout ce que nous avons donc à faire est d’utilise l’opérateur retry.
Dans l’exemple suivant, nous allons faire une requête et si elle échoue, on va réessayer 3 fois :
const http$ = this.http.get<any>('http://localhost:8080/api');
http$
.pipe(
retry({ ①
count: 3, ②
}),
catchError(err => { ③
return throwError(err);
})
)
.subscribe({
next: res => console.log('HTTP response ok.', res), ⑤
error: err => console.log('HTTP Error.', err), ④
complete: () => console.log('HTTP request completed.') ⑥
});
}
}Si on regarde dans la console, on voit bien 4 requêtes échouées (1 + 3 essais) :

Même la fonction rappel de subscribe() délivre son message à la fin des 3 tentatives :
[Log] HTTP Error. – HttpErrorResponse {headers: HttpHeaders, status: 0, statusText: "Unknown Error", …} Examinons en détail le cheminement :
- l’opérateur retry souscrit à l’« Observable » http$ (①)
- si aucunes erreurs n’est émise, l’opérateur retry est comme « transparent », c’est à dire qu’il reproduit en sortie les mêmes valeurs que celles qu’il reçoit
- dans ce cas le flux se termine par la fonction idoine de rappel de subscribe() (⑤), puis est définitivement complété (⑥)
- si une erreur survient, elle est « captée » par l’opérateur retry; ce dernier re-souscrit immédiatement l’« Observable » http$
- si une erreur survient de nouveau, le même schéma se répète
- l’opérateur retry fera 3 tentatives (car la propriété count est réglée à 3), puis émettra un « Observable d’erreur » qui sera intercepté car catchError (③)
- catchError se contente ici de retourner un « Observable d’erreur » (il n’y a pas de side effect) puis l’« Observable » http$ se termine en erreur en invoquant la fonction idoine de rappel de subscribe() (④)
Stratégie « nouvelle tentative différée »
Améliorons les choses. Ajoutons un délai d’une seconde entre chaque tentative.
Cette stratégie est utile pour essayer de récupérer de certaines erreurs telles que, par exemple, des requêtes réseau échouées causées par un trafic élevé sur le serveur.
Dans les cas où l’erreur est intermittente, nous pouvons simplement réessayer la même demande après un court délai, et la demande peut passer une deuxième fois sans aucun problème
L’opérateur timer
Pour comprendre le fonctionnement de l’opérateur timer, examinons son diagramme :
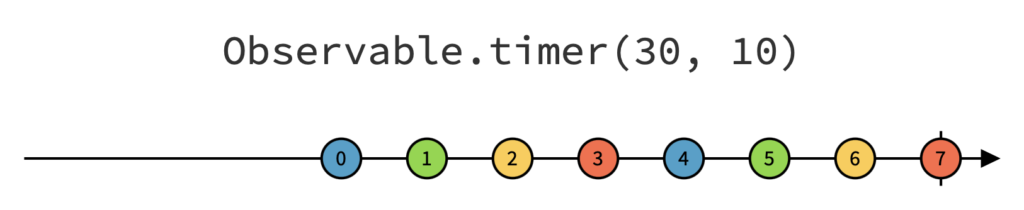
Notez que le deuxième argument est facultatif, ce qui signifie que si nous le laissons de côté, notre « Observable » n’émettra qu’une seule valeur (0) après 30ms, puis se terminera.
L’opérateur timer semble le candidat idoine pour notre besoin.
L’opérateur delay
Pour comprendre le fonctionnement de l’opérateur delay, examinons son diagramme :
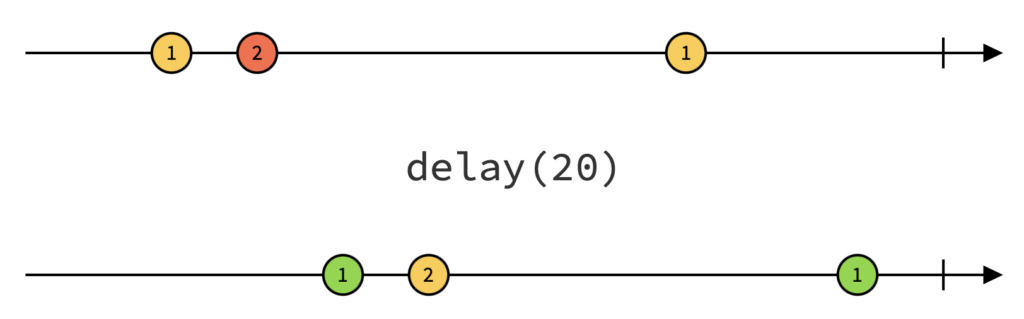
Le fonctionnement de cet opérateur est trivial : toutes les valeurs émises en entrées sont restituées à l’identique après un temps donné (ici 20ms).
Essayons d’assembler tout ça pour atteindre notre objectif qui est de différé les tentatives :
const http$ = this.http.get<any>('http://localhost:8080/api');
http$
.pipe(
retry({
count: 3,
delay: () => { ①
console.log('Retrying...'); ③
return timer(1000); ②
},
}),
catchError(err => {
return throwError(err);
})
)
.subscribe({
next: res => console.log('HTTP response ok.', res),
error: err => console.log('HTTP Error. Stop after 4 attempts.', err),
complete: () => console.log('HTTP request completed.')
});
}
}Dans la console, on peut maintenant voir ceci :
[Log] Retrying… (main.js, line 77)[Log] Retrying… (main.js, line 77)[Log] Retrying… (main.js, line 77)[Log] HTTP Error. Stop after 4 attempts. – HttpErrorResponse {headers: HttpHeaders, status: 0, statusText: "Unknown Error", …} Examinons en détail le cheminement :
- le cheminement est très proche de la stratégie précédente
- la différence est que nous introduisons un délai entre chaque tentative à l’aide du paramètre delay de l’opérateur retry (①)
- la fonction de rappel que nous définissons renvoie un « Observable » qui devra émettre des valeurs à des intervals réguliers ou non
- comme nous souhaitons des tentatives espacées régulièrement dans le temps, l’opérateur timer est le parfait candidat (②)
- donc au lieu de faire immédiatement une nouvelle tentative, l’opérateur retry va attendre 1 seconde avant de re-souscrire à l’« Observable » http$ en cas d’erreur
- la limite de 3 tentatives est encore présente comme précédemment
- on affiche un petit message dans la console avant chaque tentative (③)
- le reste du traitement est similaire à la stratégie précédente
Dans la console, le même affichage :
[Log] Retrying… (main.js, line 77)
[Log] Retrying… (main.js, line 77)
[Log] Retrying… (main.js, line 77)
[Log] HTTP Error. Stop after 4 attempts. – HttpErrorResponse {headers: HttpHeaders, status: 0, statusText: "Unknown Error", …}On pourra visualiser l’évolution dans l’onglet réseau :

Comme nous pouvons le voir, les tentatives n’ont eu lieu qu’une seconde après l’apparition de l’erreur, comme prévu.
Conclusion
A travers cet article, j’ai essayé de vous présenter plusieurs stratégies pour bien gérer ses erreurs avec Angular / RxJs.
Comme nous l’avons vu, comprendre la gestion des erreurs RxJs consiste avant tout à comprendre les principes fondamentaux du « contrat Observable ».
Nous devons garder à l’esprit qu’un flux donné ne peut se mettre en erreur qu’une seule fois, et cela est exclusif avec l’achèvement du flux ; une seule des deux éventualités se produira.
Afin de récupérer d’une erreur, le seul moyen est de générer d’une manière ou d’une autre un flux de remplacement comme alternative au flux sortant erroné, comme cela se produit dans le cas des opérateurs catchError ou retry.
Si vous avez des questions ou des commentaires, faites-le moi savoir dans les commentaires ci-dessous et je vous répondrai.
Merci pour ces explications, vous êtes un as 👌🏻